大模型微调快速上手
这篇文章将完成一个大模型微调的快速上手,我们会用微软的Phi-3 Mini 4k量化模型,通过微调让实现将英语翻译成Yoda语。
本章将学到以下内容
- 使用BitsAndBytes加载量化模型
- 使用Hugging Face的peft配置低跌适配器(LoRA)
- 加载并格式化一个数据集
- 使用Hugging Face的”监督微调训练器(SFTTRainer)“来微调模型
- 使用微调后的模型来将英语翻译成Yoda语
环境准备
我们后面的学习使用Jupyter作为开发调试工具,所以你需要安装一个VS Code(或者其他IDE)然后配置Jupyter开发环境。这里建议安装Conda作为运行环境。
导入依赖
以下是所有需要用到的Python以来,如果你使用了conda,需要先安装它们。
1 | !pip install transformers==4.56.1 peft==0.17.0 accelerate==1.10.0 trl==0.23.1 bitsandbytes==0.47.0 datasets==4.0.0 huggingface-hub==0.34.4 safetensors==0.6.2 pandas==2.2.2 matplotlib==3.10.0 numpy==2.0.2 |
然后在Jupyter文件的开头导入如下依赖
1 | import os |
加载基础量化模型
量化模型(Quantized Model)是指通过 降低模型权重和激活值的数值精度 (如从32位浮点数降低到8位整数或更低)来减少模型大小、加速推理速度并降低内存/显存占用的深度学习模型。
在这个例子中,我们只是完成一个语言翻译的任务,一个量化模型的精度足够完成任务,而且量化模型占用的硬件开销要小的多。
这里,我们加载量化模型时,会创建一个BitsAndBytesConfig实例quantization_config,它将作为from_pretrained()方法的参数。下面是示例代码:
1 | # os.environ["HF_ENDPOINT"]="https://hf-mirror.com" |
上面这段代码定义了一个 BitsAndBytesConfig 配置对象,用于 配置模型的4位量化参数 。BitsAndBytes 是 Hugging Face 生态中的量化库,专为大语言模型(LLM)设计,能大幅减少模型内存占用,使其在消费级 GPU 上运行。以下是各参数的详细解释:
load_in_4bit=True: 它的作用是启用4位精度量化加载模型,将模型权重从默认的32位浮点数(FP32)压缩为4位精度,内存占用减少至原来的1/8(理论上)bnb_4bit_quant_type="nf4":它的作用是指定4位量化的类型。其中"nf4" (Normalized Float 4)是专为 大语言模型权重 设计的4位格式。相比传统的4位整数(INT4), nf4 能更好地捕捉权重的分布特性(尤其是接近零的小值),实验证明, nf4 在LLM上的量化精度损失更小。bnb_4bit_use_double_quant=True:它的作用是启用双重量化(Double Quantization)。从技术原理上说。第一重:将权重量化为4位精度,第二重:对量化过程中使用的缩放因子(scale)再次进行量化(通常为8位)。通过这个参数设置,进一步减少量化后的模型大小(约额外减少0.5%~1%的内存),几乎无精度损失。bnb_4bit_compute_dtype=torch.float32: 它的作用是指定模型计算时使用的数据类型。虽然权重以4位存储,但 计算时会临时转换为该参数指定的精度。可选值包括torch.float32 (默认)、 torch.float16 、 torch.bfloat16。关于这个参数的配置:- torch.float32 :兼容性最好,精度最高,但速度较慢
- torch.float16 :速度更快,适合支持FP16的GPU(如NVIDIA Ampere及以上架构)
- torch.bfloat16 :适合支持BF16的GPU(如NVIDIA A100、H100)
repo_id='microsoft/Phi-3-mini-4k-instruct' 是一个轻量级的量化模型,它基于Phi-3数据集训练而来,我们这里用了它的mini-4k-instruct版本。其中:
- mini 表示是最小规模版本
- 4k 表示它的上下文窗口支持4096个token
- instruct 表示经过指令微调,适合对话和任务执行
model=AutoModelForCausalLM.from_pretrained(...)这句是从 Hugging Face Hub 下载并加载预训练的因果语言模型(Causal LM,如GPT系列),其中: - repo_id :指定要加载的模型标识符(即上一行定义的 microsoft/Phi-3-mini-4k-instruct )
- quantization_config=bnb_config :应用之前定义的4位量化配置( BitsAndBytesConfig ),实现模型压缩
- device_map=”cuda:0” :指定模型加载到的设备。”cuda:0” 表示第一个GPU(索引为0),若设为 “auto” ,则会自动分配到可用的GPU(如有多张GPU时),若设为 “cpu” ,则加载到CPU(速度会显著变慢,仅用于无GPU环境)。
上面这段代码执行后:
- 首次执行时,会从 Hugging Face Hub 下载 microsoft/Phi-3-mini-4k-instruct 的模型文件(权重、配置、分词器等)。下载的文件会缓存到本地(默认路径: ~/.cache/huggingface/hub/ ),后续执行时直接从缓存加载
- 然后进行量化处理。应用 bnb_config 中的4位量化配置( load_in_4bit=True 、 quant_type=”nf4” 等),将模型权重从原始的32位浮点数(FP32)压缩为4位精度(NF4格式),启用双重量化以进一步减少内存占用。
- 然后分配设备。将量化后的模型加载到指定的GPU( cuda:0 ),加载过程中会自动处理模型的层分布,确保所有参数都转移到GPU上。
- 最终结果。model 变量成为一个可直接使用的量化模型实例。内存占用显著减少:例如,3.8B参数的模型在FP32下约需15GB显存,4位量化后仅需约2GB(理论值)。模型可直接用于推理或结合PEFT方法进行微调。
运行上面的代码后,我们来看一下模型占用的空间有多大。
1 | print(model.get_memory_footprint()) |
输出结果为
1 | 2206341312 |
尽管已进行量化处理,该模型仍占用略超2GB的内存。量化过程主要针对Transformer解码器模块(某些情况下亦称为“层”)中的线性层进行优化:
1 | model |
输出结果为
1 | Phi3ForCausalLM( |
一个量化模型可以直接用于推理,但是它不能被拿来进行训练。那些Linear4bit层占用的空间要少得多,这正是量化的核心目的;然而,我们无法更新它们,也就不能直接进行训练。所以,我们要给它加上一些东西,也就是接下来要用到的适配器。
配置低跌适配器(LoRA)
低秩适配器(LoRA,Low-Rank Adaptation)是一种 参数高效的大模型微调方法 ,核心目标是在 不训练完整模型参数 的前提下,通过调整少量额外参数实现模型的任务适配,从而大幅降低计算和内存需求。
LoRA 的关键思想是 将模型权重的更新量限制在低秩空间 中,具体操作如下:
- 原始模型权重 :假设模型某一层的权重矩阵为 $W_0$ ,维度为 $d \times d$ ,参数为 $d^2$
- 低秩分解 :引入两个小矩阵: $A(d \times r)$ 和 $B(r \times d)$ ,其中 $r \ll d$ ( $\ll$ 是远小于的意思, r 称为秩 ,通常取 4~64)
- 权重更新 :微调时,仅训练 A 和 B ,原始权重 $W_0$ 冻结。前向传播时,实际使用的权重为 $W_0 +AB$
参数节省效果 :假设 $d = 10000$ , $r = 8$ ,则可训练参数从 $10000^2 = 10^8$ 减少到 $2 × 10000 × 8 = 1.6 × 10^5$ (仅为原参数的 0.16%)
LoRA的适配器通常是普通的线性层,它们可以非常方便的被更新。这里的优势在于这些适配器比起量化后的层来说,要小的多,因此效率更高。
因为量化后的层是冻结的(也就是说它们不能被更新),因此在量化模型上配置一个LoRA适配器可以显著减少整体的训练参数数量。
我们可以通过下面三个不收来配置LoRA
- 调用
prepare_model_for_kbit_training()函数以提高训练过程中的数值稳定性。 - 创建一个
LoraConfig实例 - 使用
get_peft_model()方法将配置应用于量化基础模型。
以下代码演示了操作步骤:
1 | model=prepare_model_for_kbit_training(model) |
这段代码是 大语言模型参数高效微调(PEFT)的核心流程 ,具体实现了对4位量化模型的预处理和LoRA低秩适配器的配置与应用。
model=prepare_model_for_kbit_training(model): prepare_model_for_kbit_training 是peft库中的函数。作用是预处理4位量化模型,确保其结构适合低精度训练。config=LoraConfig(...)中LoraConfig也是peft库中的函数,其作用是配置 LoRA 低秩适配器的参数,定义如何向模型注入可训练的低秩矩阵。- r=8 :LoRA 的秩(低秩矩阵的维度),控制可训练参数的数量。 r 越小,参数量越少(效率越高),但可能影响模型性能(常见值:4~64)。
- lora_alpha=16 :LoRA 的缩放因子,用于调整 LoRA 权重的贡献强度(通常设为 r 的 2 倍,如 r=8 时 lora_alpha=16 )。
- lora_dropout=0.05 :LoRA 层的 dropout 率,随机丢弃 5% 的 LoRA 输出,避免过拟合。
- bias=”none” :指定是否训练偏置参数。 “none” 表示不训练任何偏置(其他选项: “all” 训练所有偏置, “lora_only” 仅训练 LoRA 相关偏置)。
- task_type=”CAUSAL_LM” :任务类型,此处为因果语言模型(如 GPT、Phi-3 等自回归模型)。
target_modules=["qkv_proj", "gate_up_proj", "down_proj", "o_proj"] :指定应用 LoRA 的目标模块(模型中需要微调的层), 它们是模型中对任务表现影响最大的部分,微调这些层能以最少的参数获得最佳效果。- “qkv_proj” :注意力层的查询/键/值投影矩阵
- “gate_up_proj” :MLP 层的门控和上投影矩阵
- “down_proj” :MLP 层的下投影矩阵
- “o_proj” :注意力层的输出投影矩阵
model=get_peft_model(model,config): 这句的作用是将配置好的 LoRA 适配器应用到基础模型(4位量化的 Phi-3 模型)上,生成最终的 PEFT 模型。它内部的操作步骤是- 冻结原始模型权重 :保持4位量化的基础权重不变,避免破坏量化精度。
- 插入 LoRA 层 :在 target_modules 指定的每个模块旁插入低秩矩阵( lora_A 和 lora_B )
- 构建 PEFT 模型 :返回一个 PeftModelForCausalLM 实例,仅包含 LoRA 相关参数可训练
- 输出模型类型 : PeftModelForCausalLM ,其内部包含原始量化模型和 LoRA 适配器
- 最后通过model输出最终生成的模型结构
1 | PeftModelForCausalLM( |
现在,量化层(Linear4bit)已转变为lora.Linear4bit模块中,量化层本身成为基础层,并添加了一些规则的线性层(lora_A和lora_B)进行混合。
这些额外的层只会使模型略微增大。然而,模型准备函数(prepare_model_for_kbit_training())将所有非量化层转换为全精度(FP32),从而导致模型体积增加20%:
1 | print(model.get_memory_footprint()/1e6) |
输出结果为
1 | 2651.074752 |
由于大多数参数已被冻结,目前仅有极小部分参数总量可进行训练,这得益于LoRA技术!
1 | train_p,tot_p=model.get_nb_trainable_parameters() |
输出结果为
1 | Trainable parameters: 12.58M |
现在模型已经具备微调的条件了,但是我们还需要另一个重要的部分:我们的数据集。
格式化数据集
我们的数据集Yoda句子 包含了720个从英语翻译为Yoda语的句子,这个数据集位于Hugging Face站点。
数据集大概的样子如下图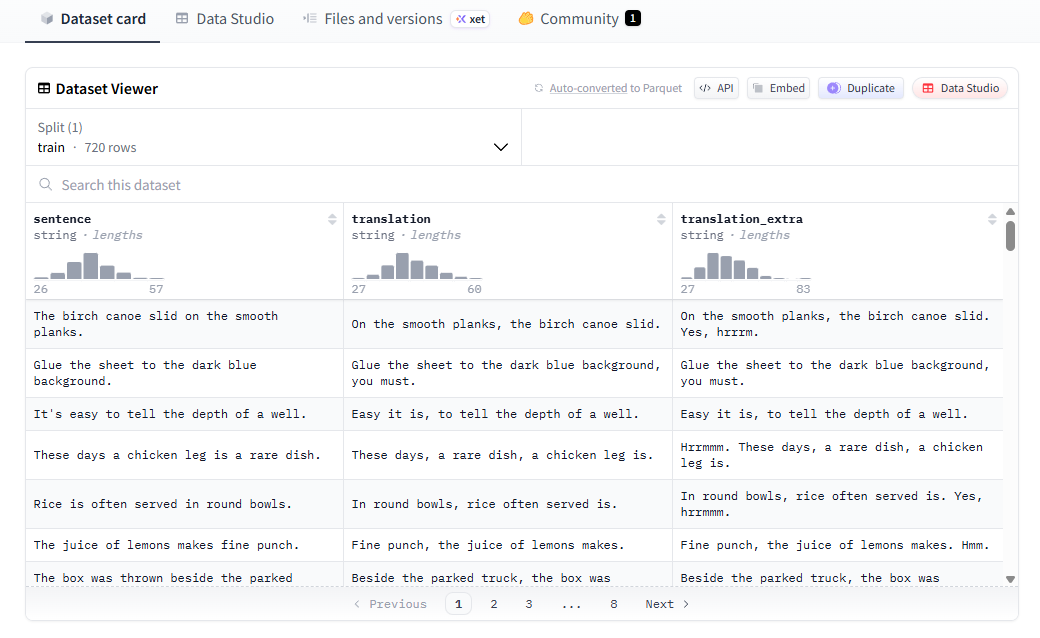
我们可以通过load_dataset()方法从Hugging Face上下载并加载这个数据集。
1 | dataset=load_dataset('dvgodoy/yoda_sentences',split='train') |
输出结果为
1 | Dataset({ |
这个数据集包括了:
- 原始的英语句子(sentence)
- 翻译成Yoda语的句子(translation)
- 保护Yesss和Hrrmm这样的额外感叹词的翻译句子(translation_extra)
我们打印数据集的第一条数据看看
1 | dataset[0] |
输出结果如下
1 | {'sentence': 'The birch canoe slid on the smooth planks.', |
后续我们会使用SFTTrainer来微调模型,它既可以把数据集处理为会话格式也可以处理为指令格式。
- 会话格式如下
1 | {"messages":[ |
- 指令格式如下
1 | {"prompt": "<prompt text>", |
因为指令模式更易于使用,我们这里用指令格式,因此需要把数据集的列做一些简单的重命名
1 | dataset=dataset.rename_column('sentence','prompt') |
上述代码中,我们把sentence重命名为promot,把translation_extra重命名为completion,然后删除了原来的translation列,最后的数据集格式如下
1 | Dataset({ |
现在来看看第一行的数据
1 | dataset[0] |
结果为
1 | {'prompt': 'The birch canoe slid on the smooth planks.', |
在内部,训练数据将从指令格式转换为会话格式:
1 | messages = [ |
输出结果为
1 | [{'role': 'user', 'content': 'The birch canoe slid on the smooth planks.'}, |
Tokenizer
在正式开始训练前,我们仍需加载与模型对应的分词器。分词器是该过程的关键组件,其作用是确定如何将文本转换为与模型训练时相同的分词形式。
对于指令/聊天模型,分词器还包含其对应的聊天模板,该模板规定了:
- 应使用哪些特殊标记,以及它们应放置在何处。
- 系统指令、用户提示及模型响应的放置位置。
- 生成提示是什么?即触发模型响应的特殊标记是什么。
下面的代码初始化了分词器
1 | tokenizer = AutoTokenizer.from_pretrained(repo_id) |
输出结果为
1 | "{% for message in messages %} |
别在意这些复杂的模版语言,该功能仅将消息组织成具有适当标签的连贯区块,如下所示(tokenize=False确保返回可读文本而非令牌ID的数字序列):
1 | print(tokenizer.apply_chat_template(messages, tokenize=False)) |
输出结果为
1 | <|user|> |
请注意,每个交互对话的开头和结尾均会使用<user|或<assistant|标记。此外,(endoftext)标记用于标示整个对话块的结束。不同模型会采用不同的模板和标记来区分句子与对话块的起止位置。现在我们已准备好进入正式的微调阶段!
使用SFTTrainer微调
对模型进行微调(无论规模大小)的训练流程与从头开始训练模型完全相同。我们既可使用纯PyTorch编写自定义训练循环,也可采用Hugging Face的Trainer进行模型微调。
不过,使用SFTTrainer(顺便说一下,它底层使用的是Trainer)要容易得多,因为它会为我们处理大部分繁琐的细节,只要我们提供以下四个参数:
- 一个模型 model
- 一个分词器 tokenizer
- 一个数据集 dataset
- 一个配置对象
前面三个对象实例我们已经有了,现在还看最后一个配置对象怎么设置。
SFTConfig
配置对象中可设置的参数众多,我们将其划分为四组:
- 与梯度累积和检查点相关的内存使用优化参数
- 数据集相关参数,例如数据所需的max_seq_length(最大序列长度),以及是否对序列进行打包处理
- 典型训练参数,如学习率(learning_rate)和训练轮数(num_train_epochs)
- 环境与日志参数,例如输出目录 output_dir(若选择将训练完成的模型推送到Hugging Face Hub,此目录将作为模型名称)、日志目录logging_dir,及日志步数logging_steps。
虽然学习率是关键参数(建议从基础模型训练时采用的初始值开始),但真正容易引发内存不足问题的,其实是最大序列长度 。
请务必根据实际应用场景,选择最短的合理最大序列长度 max_seq_length。在我们的例子中,无论是英文句子还是Yoda式的表达,都相当简短,64个标记的序列完全足以涵盖提示、补全以及额外的特殊标记。
创建SFTConfig的代码如下
1 | sft_config = SFTConfig( |
SFTTrainer
现在我们终于到了模型训练阶段了。我们将创建一个实例来微调训练模型。
1 | trainer = SFTTrainer( |
SFTTrainer已对我们的数据集进行预处理,因此我们可以查看内部结构并了解每个小批量数据的组装方式:
1 | dl = trainer.get_train_dataloader() |
上面的代码中通过获取数据加载器来查看批次数据结构
1 | batch['input_ids'][0], batch['labels'][0] |
下面是输出结果
1 | (tensor([ 797, 263, 12003, 5650, 19548, 29892, 3638, 278, 6433, 29892, |
可以看到数据集已经被转换为张量了。
下面开始基于这个数据集进行微调训练。
1 | trainer.train() |
如下图所示,我们可以看到损失率逐渐下降,经过10个迭代,模型微调结束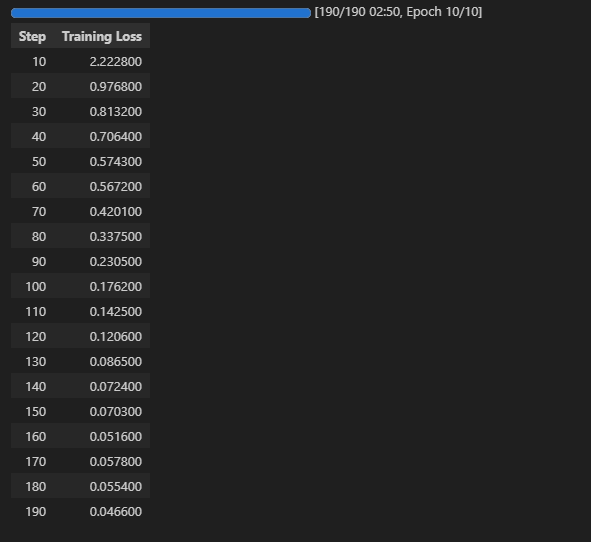
查询模型
现在,我们的模型应该能够根据我们给出的任何简短句子生成类似尤达大师的回应。因此,模型需要输入内容格式正确。我们需要创建一个“消息”列表——这里指用户发送的对话内容——并提示模型进入写作模式。这就是add_generation_prompt参数的作用:它会在对话末尾添加assistant|指令,让模型预测下一个词——并持续进行预测,直到生成(内文)标记为止。下方的辅助函数会组装对话格式的消息,并应用聊天模板,最后在末尾添加生成提示。
1 | def gen_prompt(tokenizer, sentence): |
我们来创建一个提示词模版
1 | sentence = 'The Force is strong in you!' |
输出结果如下
1 | <|user|> |
提示似乎大致正确;让我们用它来生成一个补全内容。下面的辅助函数执行以下操作:
- 该模块将提示词分词为一个由token ID组成的张量(由于聊天模板已预先添加标记,因此add_special_tokens参数设置为False)。
- 将模型设置为评估模式。
- 该方法调用模型的generate()函数生成输出(生成的标记ID)。
- 它能将生成的token ID解码为可读文本。
1 | def generate(model, tokenizer, prompt, max_new_tokens=64, skip_special_tokens=False): |
现在终于可以使用我们微调后的模型来生成翻译内容了
1 | print(generate(model, tokenizer, prompt)) |
输出结果为
1 | <|user|> The Force is strong in you!<|end|><|assistant|> Strong in you, the Force is.<|endoftext|> |
保存适配器
训练完成后,您可通过调用训练器的save_model()方法将适配器(及分词器)保存至磁盘。该方法会将所有内容保存至指定文件夹:
1 | trainer.save_model('local-phi3-mini-yoda-adapter') |
通过下面的代码可以查看保存的模型文件都有哪些
1 | os.listdir('local-phi3-mini-yoda-adapter') |
输出结果为
1 | ['README.md', |